llama.cpp Architecture
Author: Stu Feeser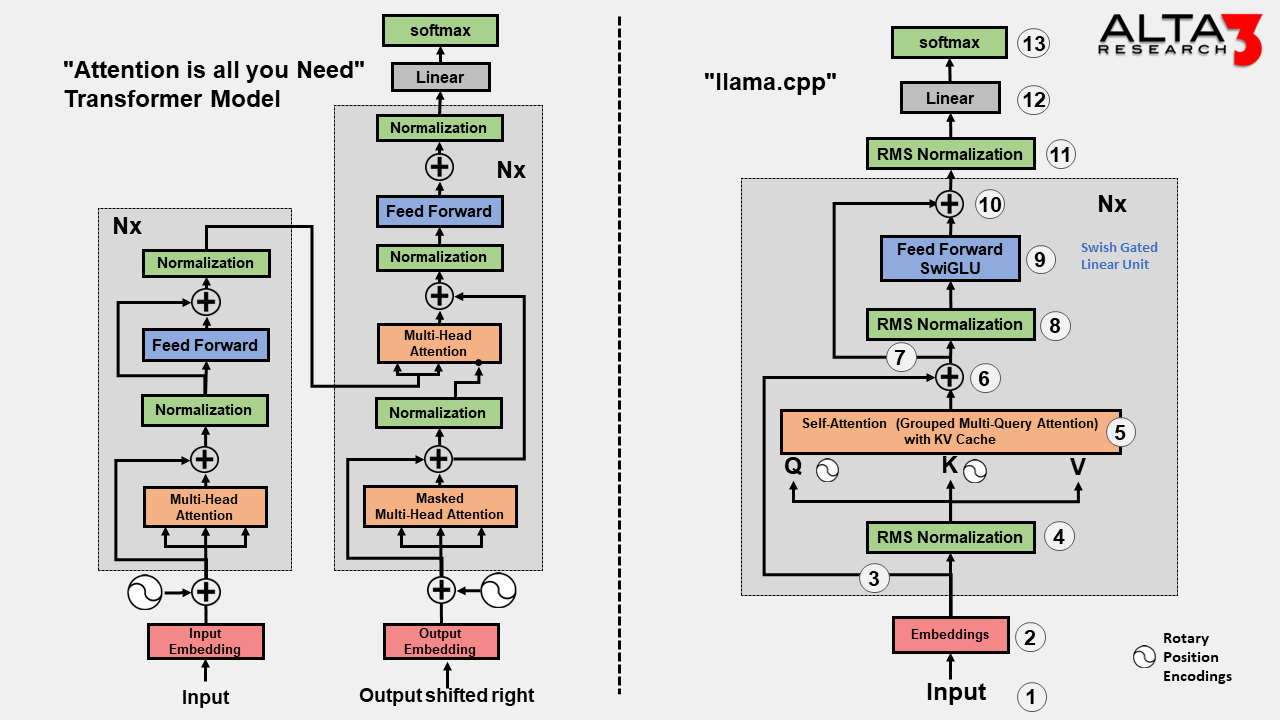
After seaching the internet for a step by step guide of the llama model, and not finding one, here is a start. Note that I analyzed each procedssing step, and then describe what each step does, why is it there, and what happens if it is removed. For easy comparison, here is the origional “Attention is all you need model architecture”, editted to break out the “add” and “Normalize” steps. In case you are wondering what normalization algorithm is used in the Attention is all you need model, I could not find one, just a clear message that normalization is necessary. On the other hand, the LLama model is very clear what algorithm is used for each step.
-
Input a Prompt
- What this step does: Provides the model with a prompt or input sequence of tokens.
- Why this step is present: Initiates the processing pipeline by supplying input data for the model to generate predictions or perform tasks.
- What happens if this step is omitted: Without input data, the model cannot perform any meaningful processing or generate outputs.
-
Calculate Embeddings:
- What this step does: Transforms input tokens into high-dimensional vector representations known as embeddings.
- Why this step is present: Converts the discrete tokens into continuous representations that capture semantic information, facilitating further processing by the model.
- What happens if this step is omitted: Without embeddings, the model lacks a continuous representation of the input data, hindering its ability to understand and process the information effectively.
-
Cache Unprocessed Active Tokens for Step 6:
- What this step does: Stores or caches the embeddings of active tokens that have not yet been processed, for later use in Step 6.
- Why this step is present: Enables efficient reuse of computed values and avoids redundant computations in subsequent steps.
- What happens if this step is omitted: Omitting this step may result in increased computational overhead and redundant computations, potentially slowing down the processing pipeline.
-
Normalization (RMSD Norm):
- What this step does: Applies Root Mean Square Deviation (RMSD) normalization to the embeddings, ensuring consistent scale and distribution across the data.
- Why this step is present: Stabilizes and standardizes the embeddings, improving the model’s ability to learn and generalize from the data.
- What happens if this step is omitted: Without normalization, the embeddings may have inconsistent scales or distributions, leading to instability in the training process and potentially hindering the model’s performance.
-
Self-Attention (Grouped Multi-Query Attention) with KV Cache (Q, K, V):
- What this step does: Performs self-attention on the embeddings, computing attention scores between tokens using a grouped multi-query attention mechanism with Query (Q), Key (K), and Value (V) vectors.
- Why this step is present: Captures relationships between tokens in the input sequence, allowing the model to attend to different aspects of the data and learn contextual dependencies.
- What happens if this step is omitted: Omitting self-attention may result in the model failing to capture important contextual relationships between tokens, leading to poorer performance on tasks that require understanding of the input sequence.
-
Add unprocessed embeddings from step 3:
- What this step does: Incorporates unprocessed embeddings from Step 3 (cached active tokens) into the processing pipeline.
- Why this step is present: Ensures that all tokens in the sequence are considered during subsequent processing steps, even if their embeddings have not yet been updated.
- What happens if this step is omitted: Omitting this step may result in the model missing important information or context from unprocessed tokens, potentially leading to incomplete or inaccurate representations of the input data.
-
Cache Unprocessed Token for Step 10:
- What this step does: Caches or stores the embeddings of tokens that have not yet been processed, for later use in Step 10.
- Why this step is present: Facilitates efficient processing and reuse of computed values, optimizing the computational resources required for subsequent steps.
- What happens if this step is omitted: Omitting this step may lead to redundant computations and increased computational overhead in Step 10, potentially slowing down the processing pipeline and reducing efficiency.
-
RMSD Normalization:
- What this step does: Normalizes the embeddings resulting from self-attention processing to maintain consistency and stability in the processing pipeline.
- Why this step is present: Ensures that the representations of tokens remain standardized and reliable for further processing by the model.
- What happens if this step is omitted: Without normalization, the embeddings may exhibit inconsistent scales or distributions, leading to instability in subsequent processing steps and potentially compromising the model’s performance.
-
Process through Feedforward Network:
- What this step does: This step passes the normalized embeddings through a feedforward neural network layer, enabling the model to learn complex patterns and relationships in the data.
- Why this step is present: This step empowers the model to capture higher-order interactions and dependencies within the input data, enhancing its predictive capabilities.
- What happens if this step is omitted: Omitting feedforward processing may result in the model failing to capture important patterns or relationships in the data, leading to suboptimal performance on downstream tasks.
- SwiGLU: SwiGLU is a Swish Gated Linear Unit that performs better than ReLU, especially in deep networks. It is a combination of Swish (developed by Google) and GLU (developed by Microsoft) that combines the best of both nonlinearities and counteracts the negative traits of each, leading to better optimization and faster convergence.
-
Add Cached Token from Step 6:
- What this step does: Incorporates cached embeddings from Step 6 (unprocessed tokens) into the processing pipeline.
- Why this step is present: Ensures that all tokens are considered during subsequent processing steps, even if their embeddings have not yet been updated.
- What happens if this step is omitted: Omitting this step may result in the model missing important contextual information from cached tokens, potentially leading to incomplete or inaccurate representations of the input data.
-
Normalization:
- What this step does: Normalizes the embeddings resulting from feedforward network processing to maintain consistency and stability in the processing pipeline.
- Why this step is present: Preserves the reliability and uniformity of the embeddings for further processing and analysis.
- What happens if this step is omitted: Without normalization, the embeddings may exhibit inconsistent scales or distributions, leading to instability in subsequent processing steps and potentially compromising the model’s performance.
-
Feed forward network:
- What this step does: Processes the normalized embeddings through a feedforward neural network layer, enabling the model to capture complex patterns and relationships in the data.
- Why this step is present: Enhances the model’s ability to learn and extract meaningful information from the input data, leading to improved performance on downstream tasks.
- What happens if this step is omitted: Omitting feedforward processing may result in the model failing to capture important patterns or relationships in the data, leading to suboptimal performance on downstream tasks.
-
Softmax:
- What this step does: Applies the softmax function to produce a probability distribution over the tokens, representing the model’s predictions for the next token in the sequence.
- Why this step is present: Generates the final output of the model, facilitating tasks such as language modeling, text generation, or classification based on the input data.
- What happens if this step is omitted: Without softmax normalization, the model’s output may not be properly calibrated as probabilities, making it difficult to interpret or use effectively for downstream tasks.